
A few days ago, a Bitcoin Core developer published a change request to remove the default size limit of data in OP_RETURN outputs. A discussion among developers and larger parts of the Bitcoin community followed, which at times got heated and hard to follow. While the Bitcoin Core maintainers seem to have reached a decision to go forward with the proposed change, others criticize the lack of consensus and potential consequences the change might have on the network.
In this article, we want to take a step back from the noise and provide some helpful context around the general concept of storing data on the Bitcoin blockchain, i.e. data not directly related to an actual Bitcoin payment. We will look at different approaches one might take to achieve this, how OP_RETURN actually works, and what this most recent discussion is really about. Let’s dive in!
Arbitrary data on the Bitcoin blockchain
The idea of storing data on the Bitcoin blockchain is as old as the network itself. However, debates on the topic have been fueled over the last few years, with growing interest (and opposition) to storing large amounts of text, images or even videos on the blockchain.
Debating whether a piece of data is “spam” or an “economic transaction” can quickly become quite subjective and even a bit philosophical. Of course, there are many transactions where the economic reasonability is strikingly obvious, such as a payment to a known merchant’s address, or a withdrawal from an exchange wallet. Some might refer to these payments as “real” Bitcoin transactions. But it’s not always that easy. Is a transaction from and to your own wallet economically relevant? How do you know a Bitcoin address is an “actual address” and not some other hidden message? Is there even a difference?
Spam… everywhere!
The Bitcoin protocol offers many places where people can store “non-transaction” data. For example, miners might use the coinbase transaction to store a text message, with the most prominent example being Satoshi Nakamoto himself in the Genesis block:
The Times 03/Jan/2009 Chancellor on brink of second bailout for bank
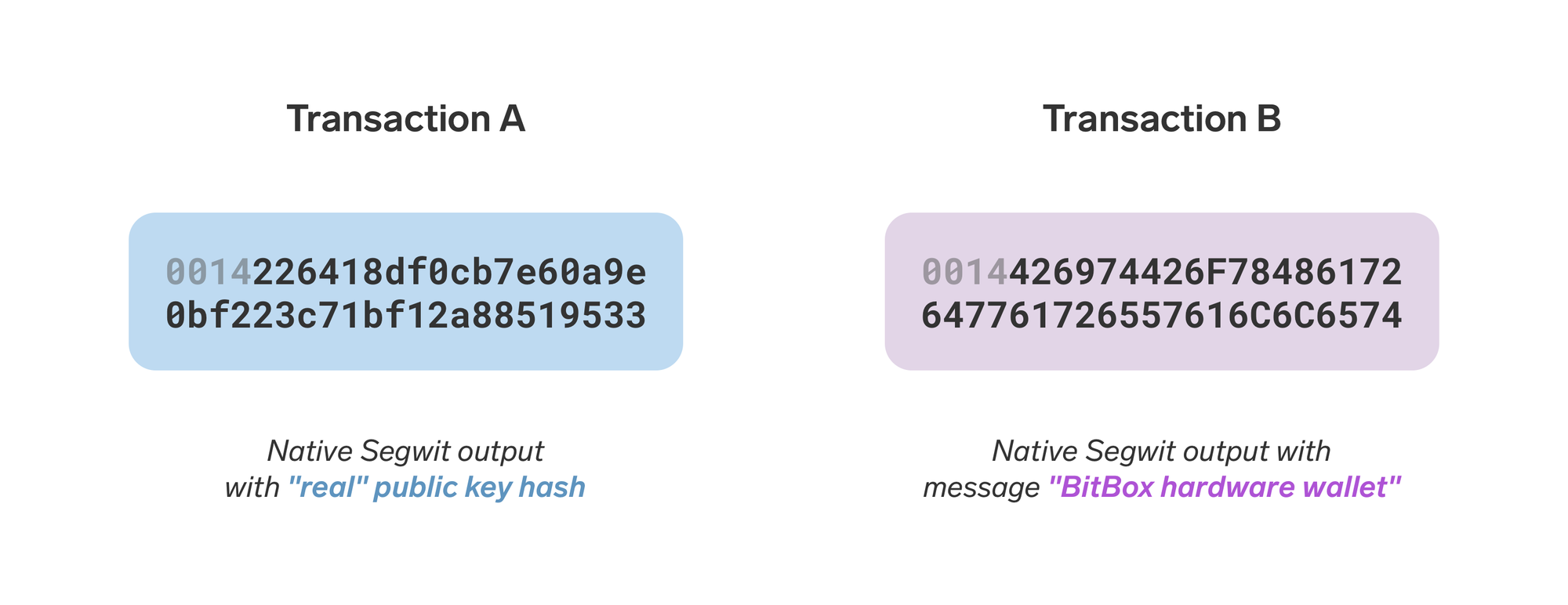
Others might (mis)use public keys and addresses themselves to store data. Typically, you would assume a public key is actually derived from a private key someone is in control of. But how would you know? Nobody can stop you from encoding a text message into a few public keys, and sending a small amount of bitcoin to them. In fact, this is exactly what users of the STAMP protocol have been doing – forever bloating the Bitcoin UTXO set with outputs that can likely never be spent.
But we’re not done yet: The Ordinals protocol, which became popular back in 2023, uses the “witness” extension of Bitcoin blocks – which is where you usually find digital signatures – to store very large amounts of data. There even is an incentive to use this part of a Bitcoin block, because of an effective fee discount due to how storage space is calculated for SegWit transactions. For example, block 774628 was almost 4 MB in size, containing a single high-resolution image of Julian Assange.

It quickly becomes apparent that, if you want to store arbitrary data on the Bitcoin blockchain, you definitely can. There are several ways to do so, and the only practical limit is the maximum block size of 4 MB. And so far we haven’t even mentioned OP_RETURN outputs!
An inconvenient truth?
Most fields in Bitcoin transactions and blocks that are not directly enforced by protocol rules may be filled with arbitrary data, unrelated to their intended purpose. This is an unavoidable circumstance, because deciding whether data is relevant requires a subjective interpretation – which is not always possible, especially in an unregulated and decentralized network like Bitcoin.

You might agree or disagree with the general concept of storing arbitrary data on the Bitcoin blockchain – and that’s fine. However, because it’s practically impossible to prevent, one can argue there are better ways to store “spam” on the Bitcoin blockchain, and there are terrible ways. Let’s take a closer look.
OP_RETURN
Despite the complicated looking name, OP_RETURN is arguably one of the features in Bitcoin’s scripting language that is very easy to understand – because it essentially does nothing. When a Bitcoin node verifies a transaction and stumbles upon an OP_RETURN output, it will treat the output as unspendable right away and move on.
At first glance, this “feature” might appear useless, but there are two main reasons for using OP_RETURN outputs:
- Burning coins: Bitcoin sent to an OP_RETURN output are locked forever and cannot be spent. It’s a provable way of “burning coins”, which might be occasionally useful for legal purposes – or just for fun if you lost a bet. For this reason, you have to be very careful to not lock away your coins by accident when creating transactions with OP_RETURN.
- Marking data as irrelevant: When it comes to storing arbitrary data, OP_RETURN is like an early indicator that tells validating Bitcoin nodes “You can safely ignore what follows”. Because the output will always be invalid, there is no reason to store its content. This is great for nodes that do not wish to store the entire Bitcoin blockchain, also known as pruned nodes. They can safely ignore and delete OP_RETURN outputs along with other , saving disk space and memory.
Remember when we talked about how it can be technically difficult to determine whether a piece of data is “irrelevant” or not? OP_RETURN essentially gives users the ability to make that decision themselves and communicate it to the network. This is arguably a good thing, because it’s more efficient than some of the alternatives mentioned previously. Even though OP_RETURN outputs still contribute to the total size of the Bitcoin blockchain, they are not added to the UTXO set, meaning nodes don’t have to constantly keep track of them.

Mempool policies
But what about this OP_RETURN “limit” that was mentioned in the beginning?
Bitcoin Core comes with several default settings and configuration options that influence the node’s behavior in the network. Some of these config options are about whether the node should relay and store a new transaction in their local mempool – these are often called mempool policies or standardness rules. Most importantly, whether a transaction is valid and can be included in a new block is an entirely different question, determined by consensus rules which are unrelated to this discussion.
As of writing this article, Bitcoin Core comes with a default limit of 80 bytes of data applied to OP_RETURN outputs, which can be changed anytime with a simple configuration option. This simply means that a node will not relay a transaction with an OP_RETURN output containing more than 80 bytes of data (or whatever the user configured), and it will not add it to its mempool of unconfirmed transactions. Of course, if such a transaction was included in a new block, the node would still accept it, since the limit is not a consensus rule.
In short, it’s currently quite difficult to broadcast transactions with large OP_RETURN outputs, as almost all nodes will not relay them due to the default limit of 80 bytes. However, this limitation has its limits, which we should keep in mind for what comes next…
- Not a consensus rule: Because transactions with larger OP_RETURN outputs are valid under consensus rules, they can be included voluntarily by miners anyway. This way, a single transaction could even include multiple OP_RETURN outputs with arbitrary sizes.This can be done by either approaching miners directly or connecting to other nodes that do not enforce the policy, making it easier for the transaction to propagate to miners. Note that miners generally have a financial incentive to include high-fee transactions, no matter what their content or context is. All it takes is a single miner willing to do so.
- Alternative methods: There are other methods to store large amounts of data which are even more difficult to avoid, such as inscriptions in witness data or public keys and hashes in standardized outputs, as mentioned before. Note that the misuse of standard outputs to hide arbitrary data is technically almost impossible to prevent, and can quickly result in a “cat-and-mouse” game of more rules resulting in even more elaborate ways to hide data.
Removing the limit
The main argument to remove the current limit of 80 bytes is its ineffectiveness to actually prevent storing data on the blockchain, as evidenced by equally effective yet worse alternatives. Simply raising the limit would be an option as well, but the same arguments and limitations could be applied to any higher limit as well, which is why the Core developers argue for a complete removal.
Actively limiting the usage of OP_RETURN outputs also actively encourages the use of alternative storage methods, leading to counter-intuitive incentives. Improving the usability of OP_RETURN essentially improves the resource requirements for Bitcoin node operators and the network’s overall efficiency. Over a decade ago, the Bitcoin Core release notes already contained this very same reasoning:
This change is not an endorsement of storing data in the blockchain. The OP_RETURN change creates a provably-prunable output, to avoid data storage schemes – some of which were already deployed – that were storing arbitrary data such as images as forever-unspendable outputs, bloating bitcoin's UTXO database.
Now that we understand the rationale behind the proposed change a bit better, we can also take a look at the other side of the argument!
So what might speak against the proposed change?
While proponents of the change emphasize efficiency and technical pragmatism, the debate around OP_RETURN has revealed a range of counterarguments that go beyond implementation details. Critics raise both philosophical and practical concerns, questioning whether the change aligns with Bitcoin’s long-term goals and whether it meaningfully addresses the actual sources of on-chain data spam.
A financial network first
Most critics want to prioritize the preservation of Bitcoin as a financial protocol, and prevent its usage as a general-purpose data layer. From this perspective, removing the OP_RETURN limit risks normalizing non-financial use and sending the wrong signal about what the blockchain is for. Even if technically harmless, they argue, lifting the limit could attract new use cases that further blur Bitcoin’s intended scope and increase pressure on node operators over time. Skeptics also question whether the change would even meaningfully reduce the negative impact of spam on the overall network.
Why remove the possibility?
Some argue that removing the default limit is acceptable, while removing the option to set a custom limit entirely is not. Given there already is a working solution for people to set a custom limitation for OP_RETURN outputs, one can argue there is little reason to remove this possibility from users who would still like to use it. After all, mempool policies are something everyone can configure on their own, following the mantra of “your node, your rules”.
Concerns about the process
The way this proposal was introduced has also drawn criticism. The speed with which the pull request is planned to be merged into the next Bitcoin Core release, combined with the removal of related configuration options for users, raised concerns about insufficient discussion. While the change does not alter consensus rules, opponents argue that shifting long-standing defaults without broad agreement undermines trust and sets a risky precedent.
When in doubt, don’t
For many, this is ultimately about caution. The change addresses a problem it may not solve, carries potential side effects, and lacks clear consensus. In such cases, critics argue, the responsible path is to maintain the current policy, keep options open, and revisit the issue only with stronger justification, different solutions or broader support. In a system like Bitcoin, where stability and predictability are paramount, sticking with the status quo is sometimes the least risky and most prudent decision.
Spam prevention
In general, the Bitcoin network has one very important mechanism to defend itself against spam: a free transaction fee market. With a constant supply of available block space, which is around 2-3 MB every ten minutes, the transaction demand regulates their priority automatically, without needing central decision-makers. Just like supply and demand lead to an ever-changing Bitcoin price, the fee market puts a price on transactions. This way, no single entity is supposed to be able to manipulate it for a long time, since no one can have an infinite amount of bitcoin to pay for it.
Conclusion
As with many discussions in Bitcoin, there is no clear right or wrong answer, only trade-offs. While the proposed change may improve how arbitrary data is handled technically, it also raises valid concerns about long-term incentives, cultural direction, and the decision-making process itself. Whether seen as a practical improvement or a risky precedent, the debate reflects the complexity of maintaining a decentralized system with diverse priorities.
Imagine a future where a large portion of the world regularly creates Bitcoin transactions. Big corporations and maybe even nation states may need to move their coins. Private users might have to create and settle their Lightning channels regularly. In short, if there is very high demand for transactions, the fee rates will be very high as well. You can argue it is quite unlikely that there will be a significant market for “useless” data on the Bitcoin blockchain in the long run. Just like it’s up to the market to decide whether Bitcoin has value, it’s up to the fee market to decide whether transactions have value.
Considering this overarching principle, the decision on limiting the size of OP_RETURN outputs – or not – may not have as big of an impact as one might think at first glance. What the removal of the limit primarily wants to achieve, is a more efficient way of dealing with larger amounts of arbitrary data. Or, in other words, choosing “the lesser evil” when compared to the misuse of standard outputs to store data.
It also serves as a great example of how debates around Bitcoin’s development can evolve and maybe even lead to higher diversity in different Bitcoin node implementations, and more awareness of how policy and consensus rules actually work. Whatever may happen, everyone will be able to choose and configure their node software the way they want to, because that’s what Bitcoin is ultimately all about.
Don’t own a BitBox yet?
Keeping your crypto secure doesn't have to be hard. The BitBox02 hardware wallet stores the private keys for your cryptocurrencies offline. So you can manage your coins safely.
The BitBox02 also comes in a Bitcoin-only version, featuring a radically focused firmware: less code means less attack surface, which further improves your security when only storing Bitcoin.

Shift Crypto is a privately-held company based in Zurich, Switzerland. Our team of Bitcoin contributors, crypto experts, and security engineers builds products that enable customers to enjoy a stress-free journey from novice to mastery level of cryptocurrency management. The BitBox02, our second generation hardware wallet, lets users store, protect, and transact Bitcoin and other cryptocurrencies with ease — along with its software companion, the BitBoxApp.